

Tra nuovi algoritmi e progressi informatici ora le macchine possono apprendere modelli sempre più complessi. Arrivano a generare dati sintetici di alta qualità come immagini fotorealistiche, e persino curriculum di esseri umani immaginari.
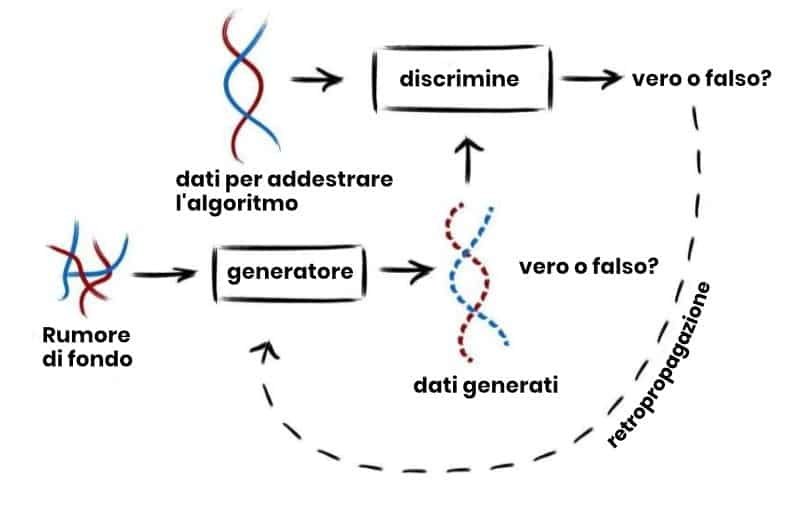
Ora uno studio pubblicato sulla rivista internazionale PLOS Genetics mostra l’uso avanzato del machine learning sui dati biometrici. Dalle biobanche esistenti, il sistema genera interi blocchi di genoma umano che non appartiene a esseri umani reali ma ha le caratteristiche di un genoma reale.
Bypassare il problema della privacy
“I database genomici esistenti sono una risorsa inestimabile per la ricerca biomedica,” dice Burak Yelmen, primo autore dello studio e Junior Research Fellow of Modern Population Genetics presso l’Università di Tartu. “Il problema è che non sono pubblicamente accessibili o protetti da procedure di applicazione lunghe ed estenuanti a causa di valide preoccupazioni etiche. Questo crea una barriera scientifica importante per i ricercatori. Un Genoma generato da macchine, un “genoma artificiale”, può aiutarci a superare il problema all’interno di un quadro etico sicuro”.
:format(jpg):extract_cover()/https%3A%2F%2Fscx1.b-cdn.net%2Fcsz%2Fnews%2F800a%2F2021%2F13-machinelearn.jpg)
Il team pluridisciplinare ha eseguito più analisi per valutare la qualità del genoma generato dal machine learning rispetto a quello reale. “Sorprendentemente, questo genoma imita le complessità che possiamo osservare all’interno di popolazioni umane reali e, per la maggior parte delle proprietà, non sono distinguibili dagli altri genomi della biobanca usata per addestrare il nostro algoritmo. Tranne per un dettaglio: non appartengono a nessun donatore di geni”, ha affermato il dott. Luca Pagani, uno degli autori senior dello studio e borsista Mobilitas Pluss.
Un Genoma generato da macchine, un “genoma artificiale”, può aiutarci a superare il problema all’interno di un quadro etico sicuro
Burak Yelmen
È genoma davvero originale o una copia “sputata”?
Lo studio prevede inoltre la valutazione della vicinanza di genoma artificiale a genoma reale per verificare se la privacy dei campioni originali è preservata. “Anche se il rilevamento di fughe di privacy tra migliaia di genomi potrebbe sembrare la ricerca di un ago in un pagliaio, la combinazione di più misure statistiche ci permette di controllare attentamente tutti i modelli. È interessante che l’esplorazione dettagliata di schemi di dispersione complessi porti a sua volta ad altri miglioramenti nella valutazione della GAN e alimenterà il campo dell’apprendimento automatico”. A dirlo è la dott.ssa Flora Jay, coordinatrice dello studio e ricercatrice del CNRS, Centro nazionale francese per la ricerca scientifica).
Tutto sommato, gli approcci di apprendimento automatico fornivano già volti, biografie e molte altre caratteristiche a una manciata di esseri umani immaginari. Ora sappiamo di più anche sulla loro biologia. Questi umani immaginari con genoma realistico potrebbero fungere da banco di sperimentazione al posto di genomi reali che non sono pubblicamente disponibili.


